
L’edizione digitale de I Capricci d’un Re nasce nel contesto del Master Infotext dell’Università degli studi di Siena e si propone di divulgare e di proporre la commedia I Capricci d’un Re di Stefano Pulvirenti, tramite un contatto diretto e quasi materiale con quanto scritto dall’autore, grazie agli strumenti che oggi l’Informatica Umanistica riesce a fornire. L’intero progetto e la codifica sono stati pensati e realizzati da Elisa Conti, studentessa del Master e discendente diretta dell’autore.
Proponiamo di seguito un breve excursus sulla nascita del progetto e sulla codifica impiegata per il testo.
Come nasce il progetto
L’idea è nata grazie alla progettazione di una Biblioteca digitale dedicata a Pulvirenti e creata sempre nel contesto del Master Infotext nell’edizione del 2022.
Si tratta di un lavoro che ha comportato la raccolta dei testi dell’autore e uno sguardo approfondito alla storia delle sue opere. Da qui nasce l’idea di un’edizione digitale de I Capricci d’un Re nella sua versione manoscritta.
La visualizzazione e il proposito
Lo strumento di visualizzazione impiegato è il software EVT1 (Edition Visualization Technology) che permette al lettore di analizzare contemporaneamente il manoscritto digitalizzato e la sua trascrizione.
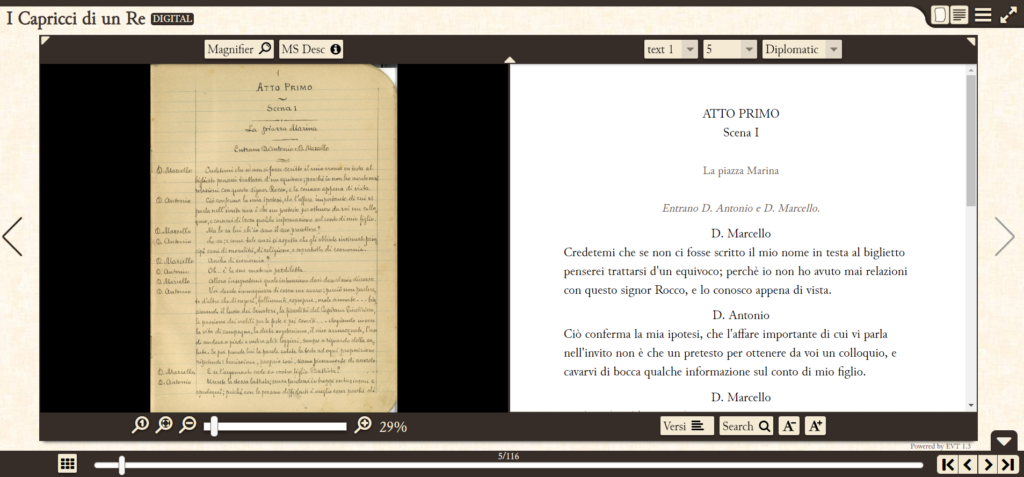
In questo modo il fruitore dell’edizione potrà egli stesso osservare la grafia dell’autore, la fattura del quaderno, gli errori del testo. Nonostante si perda l’esperienza tattile dello sfogliare il manoscritto o non si sia direttamente esposti dell’aura di cui parla Walter Benjamin[1], grazie ad una visualizzazione di questo tipo è possibile vivere un’esperienza maggiormente autentica rispetto alla lettura della sola trascrizione del testo.
Il proposito è dunque di portare il lettore dentro il testo e sulla sua superficie materiale intrisa di un inchiostro che può egli stesso osservare.
La codifica
La codifica impiegata è XML-TEI. Non è stato utilizzato uno schema TEI specifico. La scelta è stata quella di privilegiare la codifica relativa alla formattazione del testo teatrale, lasciando spazio anche alla codifica di frammenti poetici in altre lingue o di elementi rilevanti per la formattazione.
I MARCATORI DEL TESTO DRAMMATICO
Sono stati utilizzati tag specifici per la lista dei personaggi <castList>,<castItem>,<castGroup> con il tag <roleDesc> per il ruolo dei personaggi. Ogni personaggio ha un xml:id che è servito nella fase di attribuzione delle battute. Alcuni personaggi sono stati inseriti da noi nella lista principale per mezzo di note in cui viene segnalato il nostro intervento.
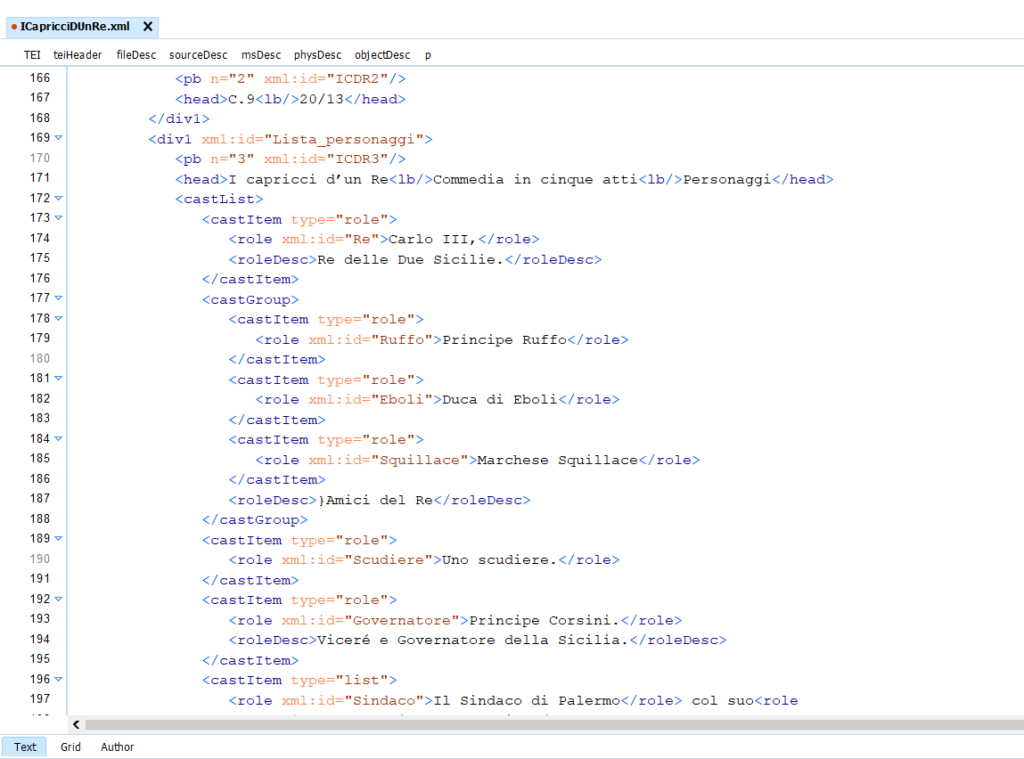
Per quanto riguarda le battute, è stato utilizzato il marcatore <sp> con gli altri due tag richiesti <speaker> e <p>. All’interno di <sp> è stato utilizzato l’attributo @who che ci permesso di inserire il rimando all’xml:id del personaggio. Per questo motivo la lista dei personaggi da noi trascritta presenta gli elementi aggiuntivi segnalati dalle note. Infatti l’autore ha inserito nuovi personaggi solo in un secondo momento, senza apportare modifiche alla lista iniziale dei personaggi. Proprio per dare omogeneità alla codifica abbiamo preferito inserire i personaggi in aggiunta ed esplicitare il nostro intervento negli appositi luoghi.
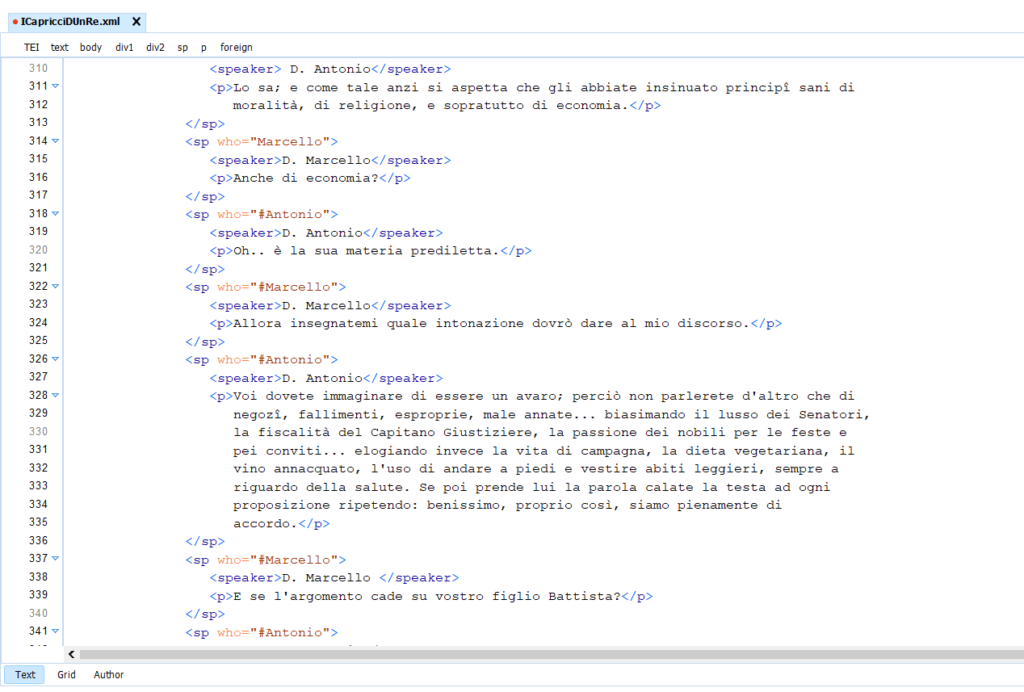
Per le entrate, le uscite dei personaggi, le attività sul palco e il modo di parlare è stato impiegato il tag <stage>. Grazie alla varietà di attributi (@entrance, @exit, @business, @delivery, @mixed, @modifier) è stato possibile distinguere le attività dei personaggi utilizzando un solo marcatore.
TAG DI FORMATTAZIONE E DI ELEMENTI LINGUISTICI
il testo è stato diviso in sezioni tramite <div>, nello specifico <div1> per gli atti e <div2> per le scene. È stato attribuito un xml:id per ogni <div> in modo da poter avere un riferimento univoco per ogni sezione.
Per indicare l’inizio di una pagina nuova abbiamo utilizzato il tag <pb> (page beginning), seguendo una nostra numerazione che comprendesse tutte le pagine del manoscritto.
Abbiamo marcato anche le parole di lingua diversa. Infatti, oltre all’italiano sono presenti parole in francese, siciliano o termini che l’autore stesso evidenzia tramite una sottolineatura. Dunque abbiamo evidenziato questi casi con il tag <foreign> con attributi @rend e @xml:lang nei casi delle parole in lingua straniera. Per i termini evidenziati dall’autore abbiamo impiegato il marcatore <hi> con l’attributo @rend.
Marcatori del testo poetico
Sono stati marcati anche i versi presenti nel testo, utilizzando i tag <lg> e <l>. Nel caso dei versi in lingua spagnola o in dialetto siciliano, sono state inserite da noi delle note con la relativa traduzione. Anche in questi casi abbiamo segnalato chiaramente il nostro intervento.
[1] Cfr. W. Benjamin, L’opera d’arte nell’epoca della sua riproducibilità tecnica, Giulio Einaudi editore, Torino 1966, nona edizione, pp. 22-23.
Home » Il progetto e la codifica